
IconQA
A New Benchmark for Abstract Diagram Understanding
and Visual Language Reasoning
(NeurIPS 2021)
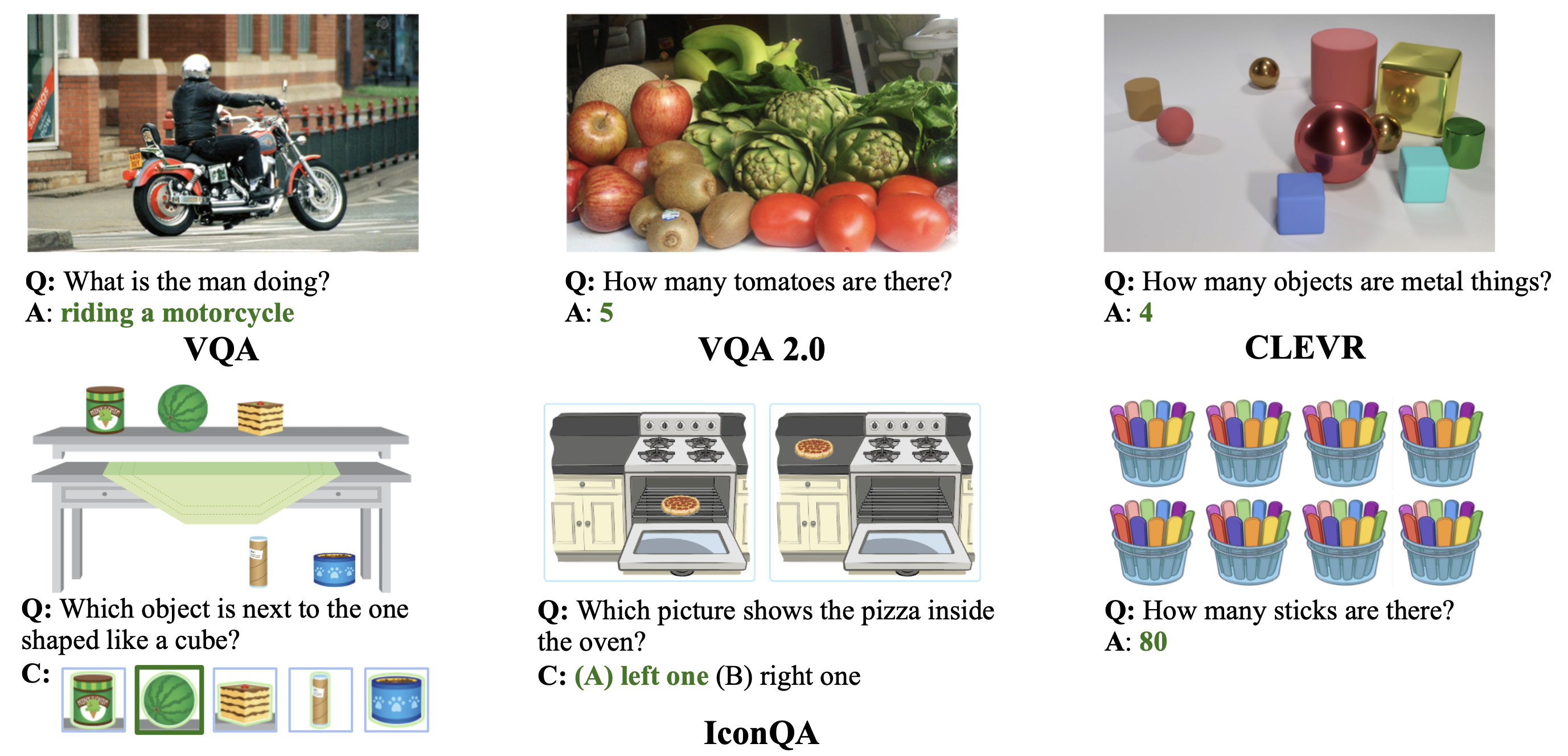
Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images in the daily-life context. In this work, we propose a new challenging benchmark, icon question answering (IconQA), which aims to highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning in real-world diagram word problems. For this benchmark, we build up a large-scale IconQA dataset that consists of three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. Compared to existing VQA benchmarks, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning.
There are three different sub-tasks in IconQA:
| Sub-tasks | Total | Train | Val | Test |
|---|---|---|---|---|
| Multi-image-choice | 57,672 | 34,603 | 11,535 | 11,535 |
| Multi-text-choice | 31,578 | 18,946 | 6,316 | 6,316 |
| Filling-in-the-blank | 18,189 | 10,913 | 3,638 | 3,638 |
IconQA provides diverse visual question answering questions that require:
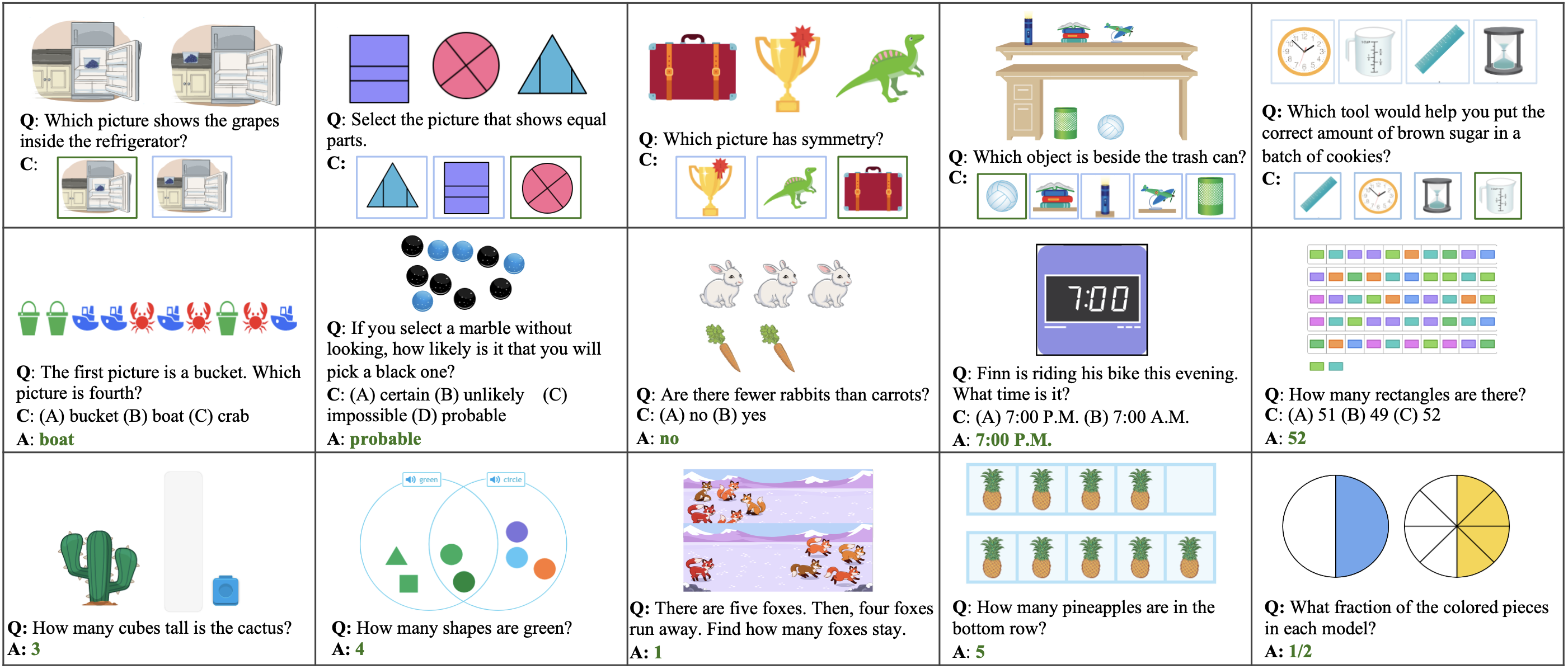
Some examples in the IconQA dataset are shown below:
For more details, you can explore the datatset and check the visualizations here: Explore and Visualizations.

In addition to IconQA, we also present Icon645, a large-scale dataset of icons that cover a wide range of objects:
These collected icon classes are frequently mentioned in the IconQA questions. In this work, we use the icon data to pre-train backbone networks on the icon classification task in order to extract semantic representations from abstract diagrams in IconQA. On top of pre-training encoders, the large-scale icon data could also contribute to open research on abstract aesthetics and symbolic visual understanding.
Our dataset is distributed under the CC BY-NC-SA (Attribution-NonCommercial-ShareAlike) license, which allows anyone to use our dataset for free under the following terms:
If you agree with the terms listed above, you can download our datasets below:
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, Song-Chun
Zhu
The 35th Conference on Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks,
2021
Paper /
PDF
/
Code

View on the github repository.
If the paper or the dataset inspires you, please cite us:
@inproceedings{lu2021iconqa,
title = {IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning},
author = {Lu, Pan and Qiu, Liang and Chen, Jiaqi and Xia, Tony and Zhao, Yizhou and Zhang, Wei and Yu, Zhou and Liang, Xiaodan and Zhu, Song-Chun},
booktitle = {The 35th Conference on Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks},
year = {2021}
}
1Center for Vision, Cognition, Learning, and Autonomy (VCLA), UCLA
2School of Computer Science and Technology, East China Normal University
3Computer Science Department, Columbia University
4School of Intelligent Systems Engineering, Sun Yat-sen University
Questions about IconQA, or want to get in touch? Contact Pan Lu at the contact page, or open up a pull request or issue on Github.

|

|

|

|

|








